
La journée du 4 avril 2024 avait bien commencé. Un petit café en main, un VS Code en plein ébullition, et de la douce musique électro dans les oreilles, tant de facteurs positifs qui ne pouvaient présager de la catastrophe à venir.
Aujourd’hui, j’aimerai vous raconter comment une journée en apparence tranquille est devenue un moment marquant de ma carrière de DevOps !

Incident
Le contexte
Je travaillais alors dans une équipe avec pour but de mettre à disposition une API Gateway globale sur AWS, avec plusieurs endpoints managés par différentes équipes. Concrètement, la mise en place de cette API Gateway était l’étape initiale du projet. Cela comprenait un record DNS qui pointait vers cette API, l’API Gateway elle-même, ainsi qu’un Cognito Authorizer configuré avec plusieurs clients.
Une fois cette API prête, des équipes externes pouvaient alors déployer leurs propres endpoints sur cette API. Pour cela, une pipeline CI/CD était mise en place, et via CloudFormation, les endpoints se rattachaient directement à l’API déjà créée.
Je simplifie au maximum, si des détails techniques vous intéressent, n’hésitez pas à me contacter !
De mon côté, en plus d’être responsable de l’infrastrcture globale de l’API, il m’arrivait de travailler ou de troubleshooter certains services.
Le début du drame
Si vous avez déjà travaillé avec CloudFormation, vous êtes peut-être familier avec le terme UPDATE_ROLLBACK_FAILED. C’est ce qui arrive lorsque vous essayez de mettre à jour une stack CloudFormation, mais que celle-ci a rencontré un problème. Elle essaiera donc de faire un rollback. Mais si ce rollback n’aboutit pas, votre stack sera alors en UPDATE_ROLLBACK_FAILED.
Et ce UPDATE_ROLLBACK_FAILED est bien embêtant, car vous ne pouvez plus relancer de déploiements tant que vous n’avez pas résolu le problème.
C’est exactement ce qui s’est passé ce fameux 4 avril 2024. Un de nos services s’est retrouvé dans cet état, et j’ai commencé à investiguer le pourquoi du comment.
Après quelques minutes, j’ai constaté que le problème venait de la ressource API elle-même. Sans trop réfléchir, et dans une optique de débloquer le problème rapidement, je me suis rendu directement sur la console AWS, sur le service API Gateway. J’ai cherché la ressource en question, et me suis empressé de la supprimer.
À ce moment précis, quelque chose de très étrange s’est produit. Un comportement inattendu qui m’a glacé le sang. Au lieu de me retrouver sur la même page, AWS m’a renvoyé sur la page principale du service API Gateway. Cette même page qui liste vos APIs disponibles, et qui affichait maintenant le nombre 0.
J’ai ainsi réalisé que je n’avais pas supprimé la ressource API, mais bien l’API Gateway dans sa totalité.
Les détails d’un échec
Jamais je n’aurais pensé commettre une telle bêtise. Et j’imagine que vous lisant ces lignes, vous vous dites la même chose.
Car pour se tromper, il fallait le faire !
Laissez-moi vous faire une reconstitution de la scène du crime. Voici ce que j’ai vu au moment où j’ai pris la décision de supprimer une ressource de l’API Gateway.
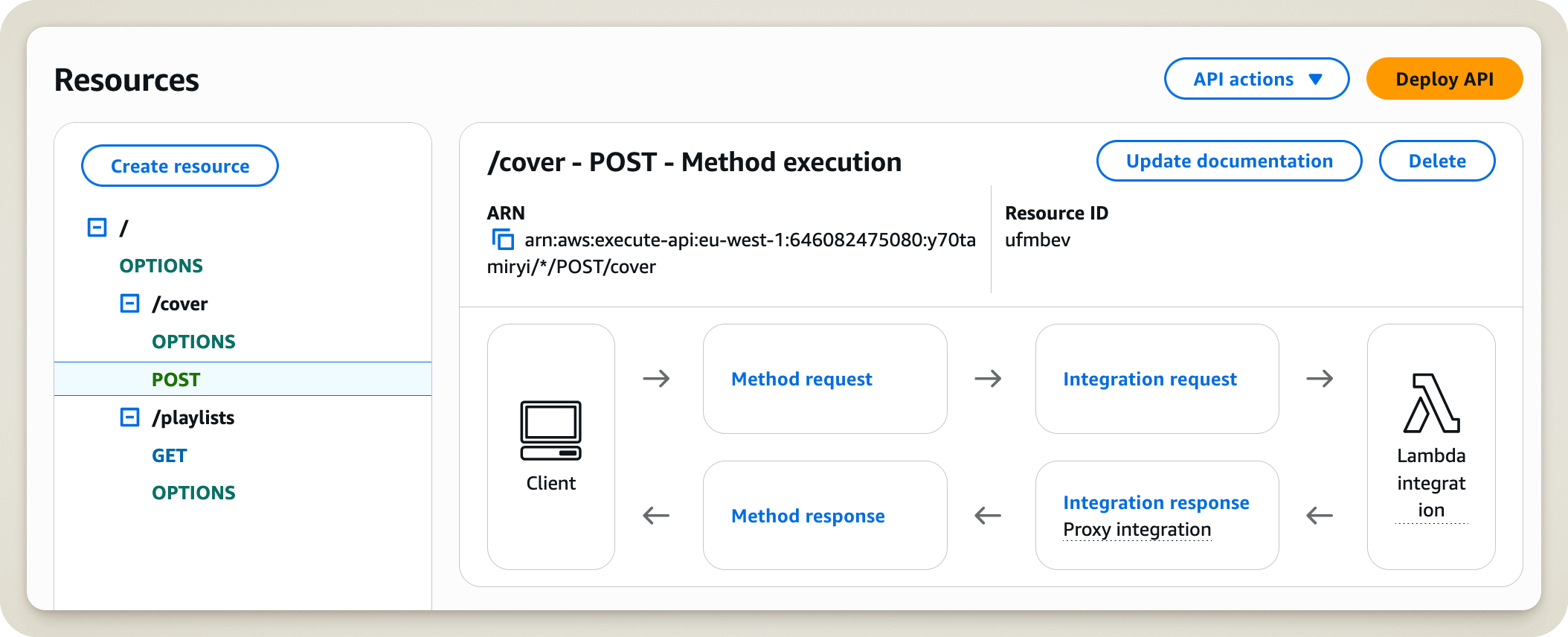
Toute ressemblance avec une situation réelle est totalement fortuite
Dans ma situation, sur quel bouton auriez-vous cliqué ? Facile ! Le bouton Delete juste à droite de la ressource !
Pour ma part (et je ne sais toujours pas ce qui m’a poussé à faire cela), j’ai préféré cliquer sur le bouton API actions. Après tout, je voulais en effet faire une action !
Et que se passe-t-il quand on clique sur ce bouton ?
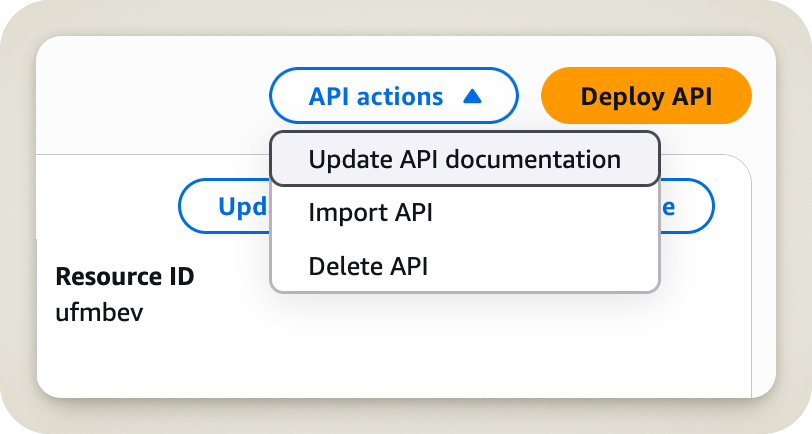
Oula ! De suite, on voit que ce n’est pas du tout ce qu’on veut faire. Mais pensez-vous que cela m’a découragé ? Absolument pas ! J’étais venu pour supprimer une ressource, et quand j’ai vu le mot Delete, je n’ai pas réfléchi plus longtemps ! J’aurais dû, car ainsi, j’aurais sûrement vu le mot API juste à côté.
Heureusement, nos amis de chez AWS ont pensé à tout ! Lorsque vous cliquez sur Delete API, on va tout de même vous demander si vous êtes bel et bien certain de vouloir supprimer cette API. Un beau message s’affiche, vous indiquant le nom de l’API en question, et vous demandant de taper le mot confirm pour valider cette opération.
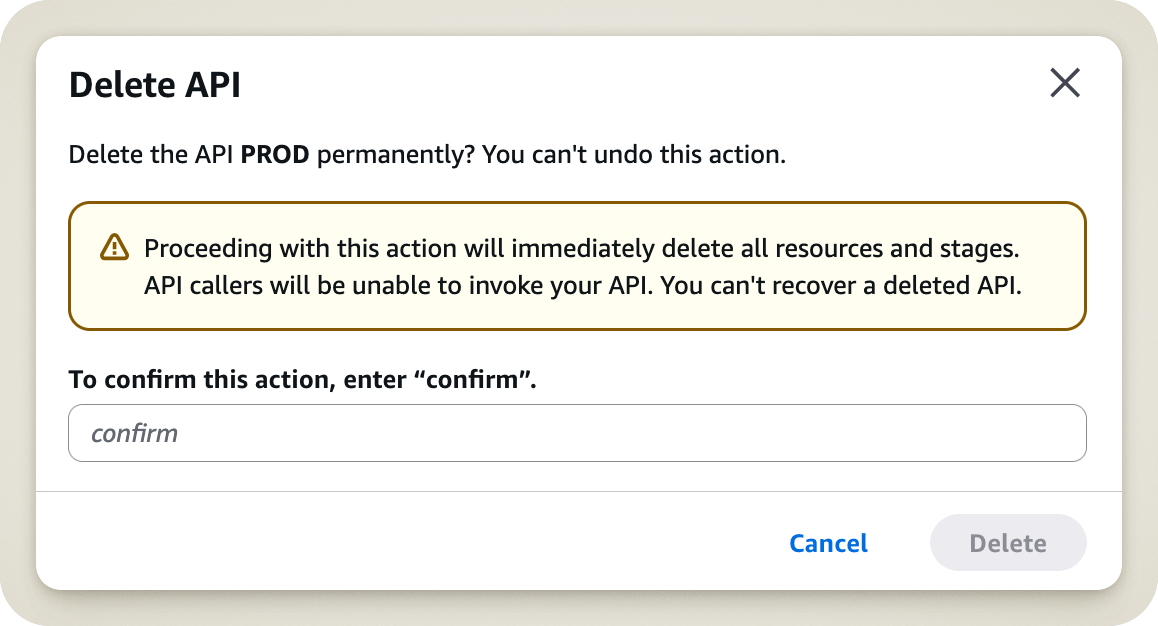
Tout ça, c’est bien beau, mais les ingénieurs d’AWS ont sous-estimé mon impatience. À ce moment-là, cette demande de confirmation n’était pas une mise en garde, mais un obstacle à mon but de supprimer ma ressource. Ni une ni deux, j’ai entré le mot confirm, et validé l’opération.
Voici donc la dernière chose que j’ai vue avant de finalement réaliser l’erreur que j’avais commise.
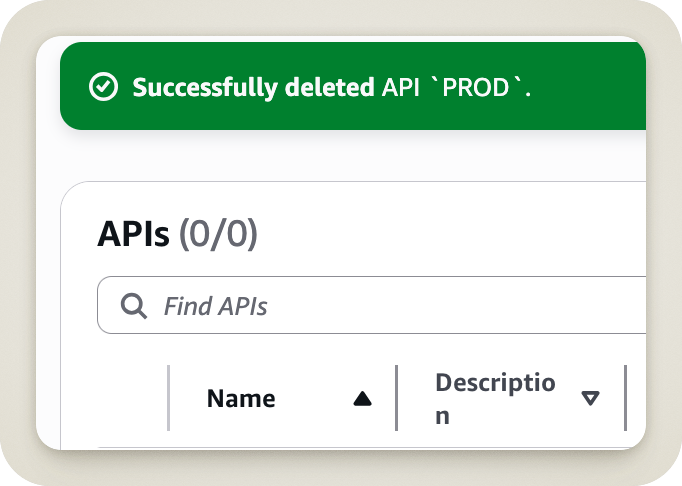
Une vision d’horreur
Je voulais absolument vous retracer ce petit parcours pour vous faire comprendre une chose : vous aurez beau mettre en place toutes les sécurités possibles, vous ne pourrez jamais rien faire contre un individu impatient, car ce dernier ne saura pas lire vos avertissements.
Alors, la prochaine fois que vous devrez faire une action somme toute inoffensive, prenez bien le temps de lire et de vous assurer que vous êtes bel et bien sur le bon chemin.
Cela étant dit, passons maintenant à une étape cruciale : la résolution de cet incident !
Résolution
Le déclic
Revenons donc sur le moment du drame. Après avoir réalisé ce qui était arrivé, j’ai eu comme un électrochoc, un éclair de génie (aucune poudre blanche n’ayant pourtant été consommée). Je savais maintenant ce que je devais faire : résoudre l’incident, mais surtout, documenter les actions que j’allais entreprendre.
Car quelques semaines plus tôt, je m’étais intéressé à l’incident GitLab de 2017, celui ayant interrompu le service pendant plusieurs heures, et résultant d’une perte de données pour certains utilisateurs. J’ai ainsi découvert le terme de Post-Morten, et leur intérêt dans ce genre de situation. Mais je garde ça pour la prochaine section de cet article.
En attendant, si vous êtes intéressés par ces sujets-là, je vous conseille la très bonne chaîne Youtube de Kevin Fang qui je le cite : “lit des postmortems et en fait des vidéos de piètre qualité”.
Rollback, impact, et communication
La première chose que je me suis dite, c’est qu’il était peut-être possible de faire une sorte de rollback directement depuis AWS, et d’ainsi réduire au maximum l’impact sur les utilisateurs. Si j’avais correctement lu le message d’avertissement plus haut, j’aurais tout de suite compris que cela était impossible (mais si je l’avais lu, je n’aurais de toute façon pas été dans cette situation).
N’ayant aucun moyen rapide et simple de revenir en arrière, j’étais maintenant confiant que j’étais face à un véritable incident ayant un impact global. J’ai donc dans un premier temps pris soin de comprendre tous les impacts que cette suppression d’API allait avoir. Dans mon cas, non seulement l’API n’était plus disponible (merci Captain Obvious), mais en plus de cela, aucun nouveau déploiement n’était possible jusqu’à ce que l’API soit de nouveau opérationnelle.
Finalement, j’ai fait en sorte d’avertir toute notre équipe interne de la situation. Ainsi, ils étaient au courant de l’incident en cours, et que j’étais en train de travailler à sa résolution.
Analyse et découverte de problèmes
Il était maintenant temps de se retrousser les manches et de trouver un moyen de redéployer cette API Gateway.
En premier lieu, je me suis rendu dans le service CloudFormation, car j’avais souvenir que cette API avait été initialement déployée via ce service. J’ai d’abord essayé de mettre à jour la stack, en pensant que cela pourrait faire revenir ma chère API comme par magie.
Évidemment, cela n’allait pas être aussi simple. La mise à jour de cette stack était maintenant impossible, car la suppression manuelle de l’API avait fait rentrer la stack dans un état “hybride” dont elle n’arrivait pas à se sortir.
La mise à jour de cette stack étant impossible, la suite logique était de la supprimer afin de la déployer à nouveau proprement. Et c’est là que les ennuis ont commencé. Cette fameuse stack CloudFormation produisait plusieurs Outputs. Deux de ces outputs étaient nécessaires à toutes les stacks “enfants” qui avaient jusqu’alors déployé leurs endpoints sur cette API. Ainsi, CloudFormation m’interdisait de supprimer ma stack, car elle pourrait impacter toutes les autres.
Après plusieurs minutes de réflexion pour essayer de trouver d’autres alternatives, cette forte interdépendance m’amena à prendre une décision difficile : supprimer toutes les stacks “enfants” de CloudFormation, pour un total de 81 stacks.
Pour couronner le tout, ces stacks “enfants” n’avaient pas de tags identifiables qui auraient pu nous permettre d’automatiser cette suppression. Heureusement, la plupart d’entre elles avaient un nom avec un préfixe reconnaissable, ce qui m’a permis de faire un bon coup de ménage sur la plupart d’entre elles.
Je vous ai parlé d’interdépendances ? Parce que ce n’est pas fini ! Certaines stacks avaient déployé des buckets S3. Et devinez quoi ? CloudFormation ne voudra pas supprimer votre stack, si votre bucket S3 n’est pas vide ! Et bien sûr, 14 stacks se sont retrouvées dans l’état DELETE_FAILED à cause de cela. Heureusement, le problème se résout assez facilement : après avoir fait un backup de chaque bucket, il suffit de les vider et de relancer la suppression de la stack.
Déploiement de l’API : Le bout du tunnel ?
Étant venu à bout de toutes ces interdépendances, il était maintenant temps de supprimer la stack CloudFormation de l’API Gateway, et de la déployer à nouveau.
La suppression se passa sans plus de problème (Dieu merci), mais évidemment, cela ne fût pas le cas pour sa création.
Déjà, parlons de la stack elle-même. Un fichier YML existait dans un repo GitHub, mais celui-ci n’avait pas été mis à jour depuis des lustres, et je savais que je ferais mieux d’utiliser la définition de la stack présente dans CloudFormation (et oui, je l’ai quand même gardée, pas fou le gars).
Cette stack ne déployait pas uniquement l’API Gateway, mais plusieurs ressources AWS (je ne rentrerai pas dans les détails du pourquoi nous avions besoin de ces ressources dans cet article), dont des Lambdas. Ces dernières se basaient encore sur Python 3.7, version avec laquelle il était impossible de se servir pour créer de nouvelles Lambdas. Heureusement, un petit upgrade en Python 3.12 sera suffisant pour qu’AWS nous laisse tranquille.
Et, à ma grande surprise, la stack se déployait maintenant sans souci !
Mais je vous la fait courte, il restait encore du pain sur la planche ! En effet, il manquait à la stack CloudFormation plusieurs ressources critiques à la bonne exécution de notre API. Des ressources qui avaient été créées à la main dans AWS directement, faisant fi de toute bonne pratique d’Infrastructure as Code (pleure en Terraform). Dans un souci de rétablissement du service le plus rapidement possible (on est DevOps, ou on ne l’est pas !), ces ressources seront donc créées une nouvelle fois à la main.
Pour finir, plusieurs composants clés faisaient référence à l’ARN de l’ancienne API en dur. Il fallait ainsi faire tout un travail d’archéologie pour trouver tous les endroits où une mise à jour vers la nouvelle API s’imposait.
Finalement, après plusieurs heures de troubleshooting, l’API était de nouveau opérationnelle, et les développeurs pouvaient à nouveau déployer leurs projets.
Cet incident aura démarré le 4 avril 2024 à 15h24 et se sera conclu le 5 avril 2024 à 08h46.
Post-Mortem et Lessons Learned
Pendant cet incident, j’ai réalisé une prise de note intensive sur les actions menées. J’avais déjà entendu parler du principe de Post-Mortem, et je pensais que cet incident serait le parfait candidat.
Si vous ignorez le principe d’un Post-Mortem, il agit comme un document retraçant les étapes de résolution d’un incident, couvrant les impacts, et la root cause, mais surtout — et à mon sens le plus intéressant — comporte une section appellée Lessons Learned. Cette section, si vous la prenez au sérieux, sera votre meilleure alliée pour construire une architecture plus robuste et plus durable.
Concrètement, vous allez noter dans cette section trois points clés : ce qui s’est bien passé, ce qui s’est mal passé, et là où vous avez eu de la chance. Et surtout, soyez honnêtes ! Même si certains points vous paraissent bêtes, ou vous font passer pour un incompétent (et je vous dis ça alors que j’ai manuellement supprimé une API, donc prenez-le avec légèreté), le but n’est pas de pointer du doigt (ce qu’on appelle aussi la blameless culture), mais de comprendre les failles dans notre système, afin de les améliorer.
« The cost of failure is education. » — Devin Carraway (Source)
Cela vous paraît peut-être encore un peu flou, alors laissez-moi vous montrer mes lessons learned de cet incident.
What went well
Pendant cet incident, deux choses se sont bien passées.
D’abord, la résolution s’est faite par un membre de l’équipe qui connaissait en profondeur cette architecture, ce qui a permis de comprendre rapidement ce qui devait être remis en place pour restaurer le service.
Enfin, il y a eu une bonne communication tout au long de cet incident. Lorsque le problème s’est présenté, il n’a pas essayé d’être dissimulé, et des mises à jour fréquentes ont été annoncées pour avertir de l’avancement de sa résolution. C’est un point très important, car non seulement vous donnez de la visibilité sur vos actions, mais par la communication, vous pouvez aussi acquérir des informations utiles à la résolution de votre incident (un collègue pourra par exemple vous pointer vers une documentation dont vous n’avez pas connaissance, ou vous donner un coup de main si nécessaire).
What went wrong
Ici, c’est la partie qui fait mal. Comme je vous l’ai dit, il faut ravaler sa fierté, et mettre en lumière tout ce qui aurait pu être mieux exécuté.
Pour cet incident, quatre choses ne se sont pas bien passées.
Pour commencer, l’infrastrucutre de cette API n’était non seulement pas consolidée dans un seul et même fichier (ou dossier), mais était en plus disséminée dans plusieurs repos GitHub. Il était ainsi très compliqué d’avoir une vue d’ensemble de ce qui était nécessaire au bon fonctionnement de cette API.
Ensuite, un gros problème résidait dans ce qu’on appelle le drift. Ce sont toutes les différences que vous avez entre votre infrastructure réelle, et votre infrastructure telle qu’elle est définie dans votre code. Idéalement, aucune modification manuelle ne doit avoit lieu, et tout doit passer par votre fichier d’Infrastructure as Code. Si cela avait était le cas, un simple redéploiement aurait permi une remise en service instantanée.
Un autre problème résidait dans la forte interdépendance de toutes les ressources. Beaucoup par exemple se basaient sur un output de la stack CloudFormation. Si vous enlevez cette stack, vous enlevez ainsi la possibilité de déployer la suite de votre infrastructure.
Enfin, l’identification des ressources liées à notre infrastructure était difficile. Notre stack déployait les ressources sans aucun tag associé, ce qui rendait compliqué la recherche de toutes les ressources nécessaires à notre API.
Where we got lucky
Cette partie peut ressembler à du positif, mais il n’en est rien ! Car vous allez ici parler des élément qui se sont bien passés, mais UNIQUEMENT car vous avez eu de la chance. Comprenez qu’à tout moment, cela aurait pû être un autre point à mettre dans la catégorie “What went wrong”. Donc soyez heureux pour cette fois, mais ne baissez pas votre garde pour autant !
Pour cet incident, trois choses se sont bien passées par chance.
Tout d’abord, l’incident a été immédiatement identifié (c’est au moins l’avantage quand on fait une boulette pareille). Mais cela aurait pû être bien pire ! Car si cette API avait été supprimée par tout autre moyen (un script d’automatisation par exemple), nous n’avions aucun monitoring en place capable de nous prévenir d’une telle chose.
Ensuite, il se trouve que la personne qui a supprimé cette API avait une excellente connaissance du projet et de l’infrastructure (je parle de moi oui, il faut bien s’envoyer quelques fleurs). Cela a permis de très vite enchaîner sur la résolution de l’incident, mais cela aurait pu se passer autrement.
Enfin, cette API était en fait notre API de dev. L’API de prod, elle, allait très bien (détail que j’ai volontairement gardé pour la fin, il paraît que c’est du storytelling). Alors certes, l’impact fût minime, mais l’incident aurait tout de même pû arriver en production, avec les mêmes problématiques de remise en service. Et cela aurait pû coûter bien plus cher.
Préparer le futur
Maintenant que vous avez pu lister les problèmes rencontrés lors de la résolution de cet incident, en tant que bon DevOps, vous vous devez d’en tirer les leçons. Notez bien tout ce qui pourrait être amélioré, mais surtout, fixez-vous un plan ! Sinon, ce ne seront que de vastes phrases sans utilité.
« Tout objectif sans plan n’est qu’un souhait. » — Antoine de Saint-Exupéry
Dans mon cas, les trois leçons clés ont été les suivantes :
- Consolidation de l’Infrastructure as Code : tout doit pouvoir être déployé en un clin d’oeil. C’est un chantier que je serai amené à compléter dans les mois qui suivirent (mais cette histoire, c’est pour une prochaine fois).
- Amélioration du monitoring et de l’alerting : si cet incident devait de nouveau arriver, il nous faut être averti rapidement afin de réagir en vitesse.
- Documentation plus claire et cohérente : n’importe quel membre de l’équipe doit pouvoir faire face à un tel incident, et cela commence par une documentation fiable et compréhensible.
Toutes ces leçons seront ensuite trackées en tant qu’issues GitHub, et je m’appliquerai à les compléter dans les mois qui suivirent (mais cette histoire, c’est pour une prochaine fois).
Conclusion
Vous l’aurez compris, un accident ça arrive. L’essentiel est qu’il soit bénéfique pour vous, et l’ensemble de votre organisation. Servez-vous en comme d’une opportunité d’apprendre et de consolider des failles qui n’était jusqu’alors pas détectées (certaines entreprises s’amusent d’ailleurs même à volontairement créer ce chaos).
Merci de m’avoir lu jusqu’au bout ! Je vous laisse ici, car j’ai d’autres infrastructures à supprimer !