
Introduction
Récemment, j’ai dû jouer les détectives sur notre compte AWS.
Une ressource était là (un Cognito User Pool), bien présente, mais personne ne se souvenait de son origine. Et évidemment, pas de tags pour nous aider (si seulement ils avaient lu mon article sur le tagging des ressources AWS).
Ma mission, si je l’acceptais : découvrir qui l’avait créée. Le problème ? L’événement datait d’il y a environ quatre mois.
Mon premier réflexe a été de me tourner vers AWS CloudTrail. Et là, premier mur : l’historique des événements n’est consultable que sur les 90 derniers jours. Raté !
Heureusement, je savais que nos logs CloudTrail étaient archivés dans un bucket S3. Mon premier réflexe : télécharger manuellement les archives du bon mois, décompresser des dizaines de fichiers JSON, et lancer un Ctrl+F en priant très fort. Autant vous dire que ce n’est ni efficace, ni agréable, ni rapide.
Je me suis donc demandé s’il n’y avait pas un moyen plus simple de chercher dans cet amas de logs, et j’ai finalement trouvé la solution parfaite : AWS Athena.
Interroger vos logs S3 avec Athena
Pour ceux qui ne connaissent pas, AWS Athena est un service de requête interactif qui facilite l’analyse de données directement dans Amazon S3 en utilisant du SQL standard. En gros, vous pouvez faire des requêtes sur des fichiers (JSON, CSV, …) comme s’il s’agissait d’une base de données traditionnelle. Plus besoin de télécharger quoi que ce soit !
L’idée est donc de “mapper” nos logs CloudTrail stockés dans S3 à une table dans Athena. Pour cela, on utilise une seule requête CREATE EXTERNAL TABLE. En suivant la documentation d’AWS sur le sujet, j’ai lancé la requête suivante dans la console Athena.
Cette requête crée une table et utilise une fonctionnalité très pratique appelée “partition projection”. Cela permet à Athena de déduire l’emplacement des logs en fonction de la date, sans avoir à gérer manuellement les partitions. C’est d’autant plus pratique quand la structure est bien standardisée comme c’est le cas avec AWS CloudTrail.
|
|
Attention : N’oubliez pas de remplacer les URLs s3://... par le chemin exact de votre bucket S3 où sont stockés vos logs CloudTrail, et d’ajuster la propriété projection.timestamp.range à la période qui vous intéresse.
L’Heure de l’Enquête : Trouver l’Information
Une fois la table créée (ce qui ne prend que quelques secondes), le plus dur est fait ! Mon enquête pouvait enfin commencer.
Je cherchais à savoir qui avait créé un UserPoolClient pour Cognito à une date précise. Ma requête SQL ressemblait donc à ça :
|
|
En quelques secondes, Athena a scanné les logs du jour demandé et m’a retourné le résultat.
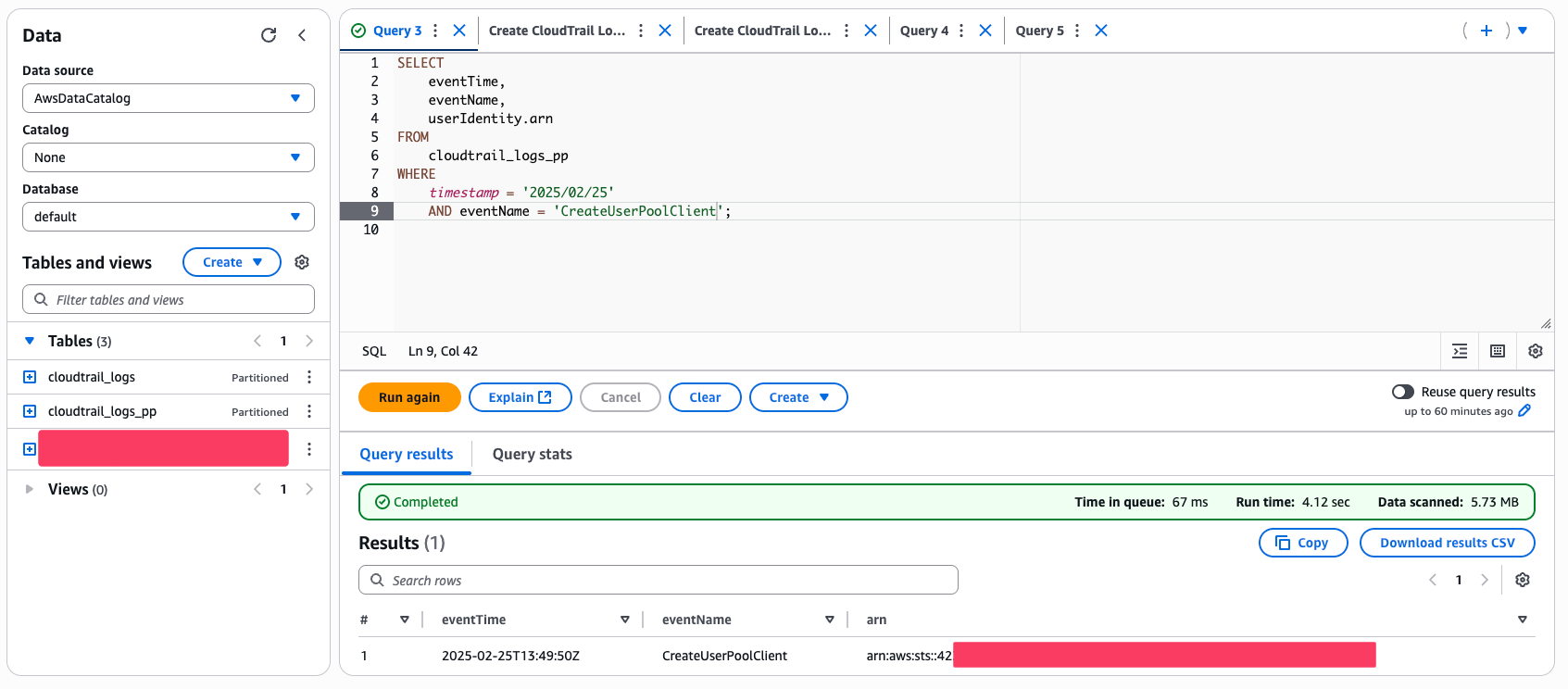
J’avais l’heure exacte, l’événement, et surtout, l’ARN de l’utilisateur qui avait effectué l’action. Mission accomplie !
Le Verdict… et le Coupable
Le plus drôle dans cette histoire ?
Après avoir mis en place cette solution et retrouvé l’information si facilement, j’ai découvert que le “coupable” qui avait créé cette ressource il y a quatre mois… c’était moi. J’avais complètement oublié !
Au-delà de l’anecdote, cette expérience m’a confirmé une chose : prendre quelques minutes pour configurer Athena sur vos logs CloudTrail est un investissement incroyablement rentable. Vous vous offrez une capacité d’audit et de recherche sur le long terme qui vous sauvera des heures de recherche manuelle le jour où vous en aurez vraiment besoin. Ne faites pas comme moi, n’attendez pas d’être coincé pour le mettre en place !