
Nous savons tous que les pipelines CI/CD sont importantes. Il semble même impossible d’imaginer un monde où l’on déploie un projet en production sans vérifier la qualité de son code et sans s’assurer que des tests ont été effectués. De plus, pour permettre aux développeurs de se concentrer sur le développement, tout cela devrait être automatisé.
Eh bien, les choses ne sont pas toujours aussi simples.
Aujourd’hui, je vais vous partager comment nous sommes passés de l’absence de stratégie CI/CD à l’intégration de plus de 100 projets Python en moins d’une minute.
La réalité
Lorsque j’ai rejoint mon entreprise actuelle, j’ai constaté que nous gérions un grand nombre de projets Python. Mais quand j’ai essayé de vérifier la CI/CD de ces projets, c’était un peu le bazar. Certains projets avaient une configuration CI/CD, mais pas beaucoup. Et ceux qui en avaient une n’utilisaient pas les mêmes règles pour vérifier la conformité du code. Il était clair que la mise en place d’une CI/CD pour chaque projet était traitée comme un effort de dernier recours. Et, pour être honnête, cela se comprend.
En effet, bien que les pipelines CI/CD soient largement reconnues pour leur efficacité, leur mise en place s’avère souvent difficile.
Mais je savais que nous pouvions changer cela d’une manière ou d’une autre. Avant de sauter dans une stratégie à mettre en place, je voulais comprendre ce qui avait empêché cette mise en place en premier lieu.
Manque de permissions
La première chose que j’ai réalisée, c’est que tous les développeurs n’avaient pas le même niveau d’accès à notre instance Jenkins. Tandis que certains pouvaient créer de nouvelles pipelines pour leurs projets, d’autres ne le pouvaient pas. Dans les grandes entreprises, ce genre de scénario n’est pas rare.
Leçon apprise : un manque de permissions ne devrait pas être un obstacle pour utiliser une pipeline CI/CD.
Manque de connaissances
Lorsque les développeurs avaient la possibilité de créer un pipeline, certains ne le faisaient pas, simplement parce qu’ils n’avaient pas les connaissances nécessaires. Il faut préciser que notre entreprise utilise une instance Jenkins comme outil officiel de CI/CD. Cet outil, bien qu’ayant fait ses preuves, reste pour le moins difficile d’usage, notamment pour les jeunes développeurs qui sont souvent familiers avec d’autres outils CI/CD (comme GitHub Actions ou CircleCI). De plus, nous n’avions pas de documentation claire sur le processus à suivre pour créer une nouvelle pipeline. Ainsi certains développeurs, de peur de casser quelque chose, préféraient ne pas prendre de risques en évitant de toucher à Jenkins.
Leçon apprise : nous devons nous assurer que les personnes sans connaissances sur Jenkins puissent utiliser un pipeline CI/CD.
Manque de temps
Mettre en place une pipeline CI/CD au début d’un projet demande du temps, chose qui peut être négligée par les chefs de projets qui veulent expédier un produit aussi rapidement que possible. De plus, il est parfois difficile de quantifier le retour sur investissement d’une pipeline CI/CD. Et si cela est difficile à prouver comme étant bénéfique pour l’entreprise, cela finit dans la boîte “on s’en occupera plus tard”. Et nous savons tous que les tâches qui finissent dans cette boîte ne verront plus jamais la lumière du jour.
Leçon apprise : la mise en place d’une pipeline CI/CD doit être rapide et simple.
Manque de guidelines claires
Enfin, j’ai jeté un œil aux projets qui eux avaient une pipeline CI/CD. Ils fonctionnaient bien, mais je pouvais clairement voir qu’ils manquaient d’une vision commune. Certains utilisaient le même formateur de code (black), mais pas toujours avec la même longueur de ligne. Certains incluaient une étape de test, d’autres non. Nous avions donc des projets n’ayant pas la même qualité et conformité de code. Et cela pouvait potentiellement créer de la confusion pour un nouveau développeur, ne sachant pas quel standard suivre.
Leçon apprise : des guidelines claires de CI/CD doivent être mises en place.
La vision globale
Après avoir analysé ce qui pouvait poser problème, il est maintenant important de penser à une solution qui puisse résoudre tous ces points, tout en respectant les meilleures pratiques de l’entreprise et en utilisant les outils à notre disposition.
Formatting
La première étape serait d’utiliser un formateur pour s’assurer que chaque ligne de code dans notre base de code soit uniforme. Cela permet d’éviter que nous ayons des standards de code différents à travers nos projets.
Auparavant, nous utilisions black comme formateur. Mais après avoir entendu beaucoup de bien sur le nouvel outil à la mode, nous avons décidé de passer à ruff, offrant les mêmes avantages que black, mais avec une exécution plus rapide (entre autres).
Linting
L’étape suivante serait d’utiliser un linter pour détecter les problèmes potentiels dans notre code. Cela nous permet d’éviter la complexité dans notre code, ainsi que de repérer les mauvaises pratiques ou les problèmes de sécurité.
Dans le passé, j’utilisais beaucoup flake8. Mais étant donné que nous utilisions déjà ruff, et que celui-ci peut également agir comme un linter, la question ne se posait plus.
Il existe de nombreuses règles que ruff peut appliquer. Nous avons décidé d’en utiliser certaines par défaut, tout en laissant une certaine liberté aux développeurs selon les projets.
Tests unitaires
Les tests sont une partie critique du développement de tout projet. Ils assurent que nous livrons un code de qualité en production, tout en nous permettant de nous assurer que notre code fonctionnera correctement.
Nous avons décidé d’utiliser pytest pour exécuter ces tests. Le répertoire de code par défaut devrait s’appeler src, et tous les tests devraient être dans un dossier tests, avec des fichiers préfixés par test_.
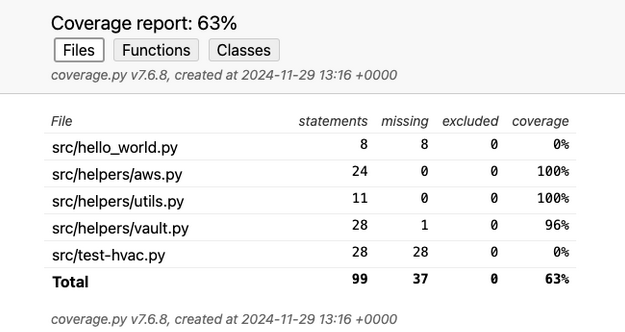
Code Coverage
Étroitement liée aux tests unitaires, le code coverage nous permet de savoir jusqu’où notre code a été testé. Cela peut nous indiquer rapidement si nous avons suffisamment testé notre code, ainsi que nous indiquer les lignes restantes à couvrir.
Comme nous utilisions pytest, nous avons décidé d’utiliser pytest-cov pour générer un coverage report, car il s’intègre parfaitement avec pytest.
Nous avons fixé le seuil de couverture minimale à 50 %. En dessous, cela risquerait de négliger des portions importantes du code, tandis qu’au-dessus, cela pourrait décourager les développeurs d’écrire les tests nécessaires.
Jenkins Organization Folders
Les étapes de notre futur pipeline étaient prêtes. Il nous restait à trouver un moyen d’appliquer globalement cette pipeline à nos repositories Python. J’ai alors cherché un moyen de le faire facilement via Jenkins.
C’est là que je suis tombé sur les Organization Folders.
Les Organization Folders sont conçus pour des scénarios comme le nôtre : scanner automatiquement une organisation (comme une organisation GitHub), filtrer les repositories que vous voulez et appliquer une pipeline Jenkins à ces derniers.
Dans notre exemple, nous pouvons rechercher tous les repositories avec le topic “python” et les identifier comme projets Python. Ils seront alors automatiquement build par Jenkins. Si un nouveau repository est créé avec ce topic, il sera également pris en charge par Jenkins.
Ainsi, en moins de 5 secondes, votre projet peut être intégré, sans avoir à le créer dans Jenkins. Tout est fait automatiquement pour que vous puissiez vous concentrer sur votre code.
Exemples et documentation
Tout cela était génial, mais je redoutais un dernier obstacle. Que se passerait-il si les développeurs essayaient cette pipeline CI/CD, tout ça pour se rendre compte que leur projet ne passaient pas ces étapes ? Sans documentation claire pour résoudre ces problèmes, ils abandonneraient ou essaieraient de corriger ces erreurs plus tard, ce qui détruirait notre objectif initial.
Je savais donc que pour embarquer les gens dans ce processus, il fallait fournir une documentation claire avec des exemples concrets, pour qu’ils puissent avoir les clés pour résoudre ces erreurs.
En particulier pour l’étape des tests unitaires, car je ne sais que trop bien que cela représente une tâche décourageante à démarrer. J’ai donc préparé un projet à l’avance avec des tests unitaires déjà prêts. N’importe qui pouvait ainsi s’en inspirer, ou direcement recopier certaines parties complexes (par exemple, le mock des appels API boto3).
La dernière étape serait de faire une présentation sur tout ce que je viens d’évoquer. Cela était essentiel pour expliquer et donner du sens à ce projet, pour que les développeurs comprennent réellement l’intérêt de tout cela, tout en s’assurant qu’ils aient toutes les clés pour être autonomes. Enfin, cela serait également l’occasion de répondre à de nombreuses questions, et assurer que tout le monde comprenne le fonctionnement de cette nouvelle pipeline.
Ce que nous avons aujourd’hui
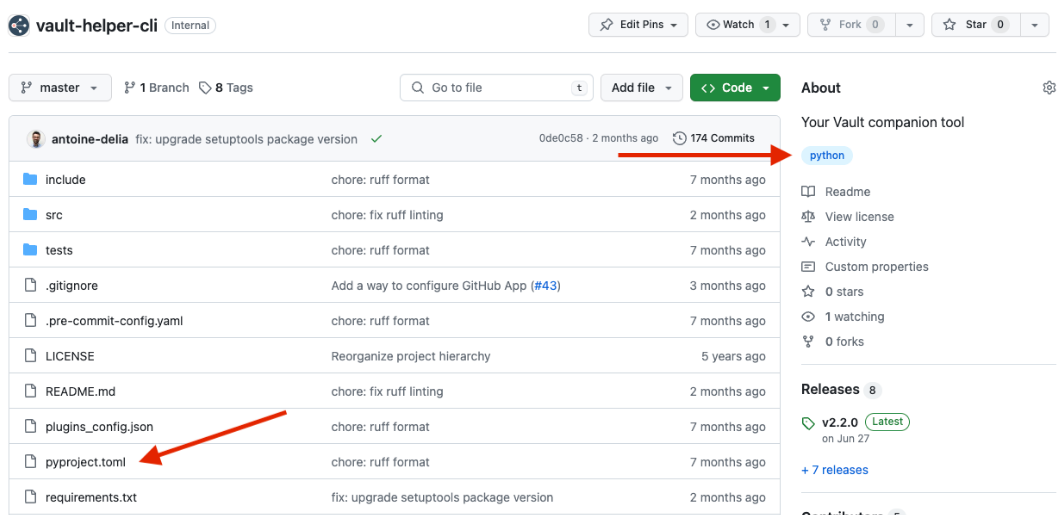
Du point de vue d’un développeur, tout ce qu’il doit faire pour ajouter une pipeline CI/CD à son projet Python est d’ajouter le topic python à son repository et de s’assurer qu’un fichier pyproject.toml est bien créé à la racine du projet.
Ces deux exigences permettent à Jenkins de savoir quels projets il doit prendre en compte. Le fichier pyproject.toml est en effet indispensable pour les étapes de ruff dans la pipeline.
Une fois cela fait, le projet Python vérifiera maintenant les problèmes de formatage, les erreurs de linting, la validation des tests unitaires et la couverture du code.
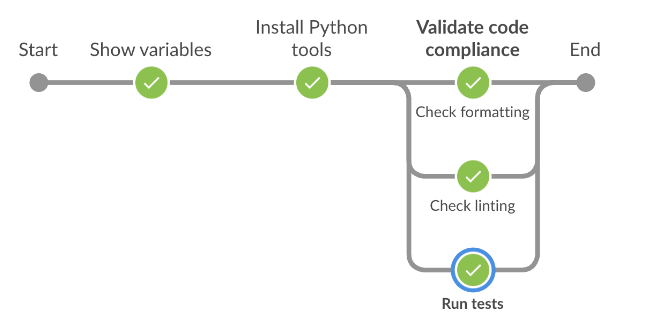
Au final, nous pouvons maintenant mettre en place des pipelines CI/CD en moins d’une minute, que ce soit pour un nouveau projet ou un projet existant !
Quelques défauts
Bien que cela simplifie beaucoup de choses, il reste encore des améliorations possibles.
La pipeline ne peut pas être imposée
Actuellement, cette pipeline CI/CD ne peut pas être imposée, car les développeurs peuvent simplement retirer le topic python. Et bien que cela soit acceptable au début (car nous ne voulons pas bloquer les développeurs dans leur travail), l’objectif reste de s’assurer que nous appliquons les mêmes bonnes pratiques à tous les projets Python.
Cela pourrait être résolu à l’avenir par l’utilisation des GitHub Rulesets.
Ces règles fonctionnent à peu près de la même manière que les règles de protection des branches, sauf que vous définissez ces règles au niveau de votre organisation GitHub.
De cette manière, nous pourrions protéger nos branches principales pour tous nos repositories qui matchent à des “custom properties” et ainsi exiger qu’ils valident leur pipeline CI/CD avant de pouvoir merger.
Les étapes de la pipeline peuvent être ignorées
Le fichier pyproject.toml est utilisé pour dire à ruff quel format il doit appliquer ou quelles règles suivre.
Et comme nous utilisons actuellement le pyproject.toml dans chaque repository, un développeur pourrait simplement enlever ces règles, contournant ainsi toutes les directives que nous essayions d’appliquer au départ.
Encore une fois, bien que nous permettions cela pour l’instant afin de prendre en compte les nombreuses corrections à apporter, à terme, nous aimerions vouloir empêcher cela.
Nous pourrions soit utiliser un fichier pyproject.toml commun et fixe, soit l’ajouter dans le fichier CODEOWNERS de GitHub pour nous assurer qu’il ne puisse être modifié sans une approbation stricte.
Et après ?
Avec tout cela en place, nous pouvons maintenant penser à l’évolution de cette pipeline.
Par exemple, notre entreprise dispose d’une instance SonarQube. Nous serions intéressés d’ajouter une étape qui pourrait analyser chaque projet à la recherche de mauvaises pratiques.
Nous explorons aussi l’utilisation de mkdocs, pour que les projets puissent partager un style commun pour la documentation.
Et une de mes évolutions préférées, nous pourrions explorer l’utilisation de uv pour installer les dépendances, car il est beaucoup plus rapide que ce bon vieux pip !
Vous avez également peut-être remarqué que, bien que j’aie parlé de CI/CD tout au long de cet article, à aucun moment nous avons parlé d’une étape qui, eh bien, déploie quelque chose (ce qui nous laisse avec une pipeline CI). Nous réfléchissons déjà à un moyen de build/deploy des packages Python vers notre gestionnaire de dépôt Artifactory, ce qui en ferait enfin une vraie pipeline CI/CD !
Enfin, nous n’avons abordé que Python dans cet article, mais la même logique pourrait s’appliquer à d’autres types de projets. Par exemple, nous travaillons également sur une pipeline CI/CD pour Terraform.
Conclusion
En abordant les problèmes de permissions, les lacunes en matière de connaissances Jenkins et l’absence de guidelignes, nous avons construit une stratégie CI/CD unifiée qui prend désormais en charge plus de 100 projets Python. Cela prouve qu’avec la bonne approche, l’automatisation est réalisable pour toute organisation.
Cela a été un long mais enrichissant parcours !
J’espère que cet article a montré la valeur des pipelines CI/CD, vous a aidé à comprendre ce qui pourrait empêcher son application et vous a donné quelques idées sur la manière de mettre en place une stratégie similaire dans votre organisation !